Local LLM Inference Server
A server for running local LLMs was built with the following hardware:
| Motherboard: | Supermicro X9DRi-LN4F+ |
| CPU (2x): | Xeon E5-2680 |
| RAM: | 96GB of some random DDR3 ECC sticks |
| GPU (2x): | Tesla P40 |
| PSU1 (motherboard): | Thermaltake Smart 700W |
| PSU2 (GPUs): | HP DPS-1200FB-1 A |
| Storage: | 3x 256GB SATA SSD |
A single 120mmx32mm blower fan was used to cool both gpus using a 3d printed shroud. Due to the GPU blower configuration and minimal CPU load, air temperature inside the case remains close to ambient. Under load, the GPUs draw an average of 150W, which results in a steady state temperature of ~57C. When running smaller models in the seven billion parameter range, the GPUs can draw over 220W, resulting in temperatures in excess of 77C. For continuous use on small parameter models, a single 120mm blower fan for both GPUs is likely insufficient.

On the software side, the P40s were run with Nvidia driver version 535.274.02 with support for CUDA version 12.2. One major limitation of the system in its current form is the lack of support for AVX2 instructions on the CPUs. The Llama.cpp version bundled with the oobabooga webui failed to run, but the backend that Ollama uses works well.
When a model is loaded into VRAM, the GPUs are set to their maximum powerstate and draw 50W at idle. For optimal energy efficiency, Ollama can be configured to unload models after a certain amount of time; if the models are cached in system RAM, loading takes between 3 and 12 seconds depending on model size. Loading from SATA SSD is incredibly slow and can take multiple minutes.
To benchmark the system, a simple token generation test was run on a variety of models with 4 bit quantization. Each model was loaded with the default parameters and given the following prompt: "Write a long essay on the pros and cons of each pizza topping." Responses ranged in the 1000-2000 token range, and each run was repeated 5 times. The token generation results are plotted below with a 95% confidence interval:
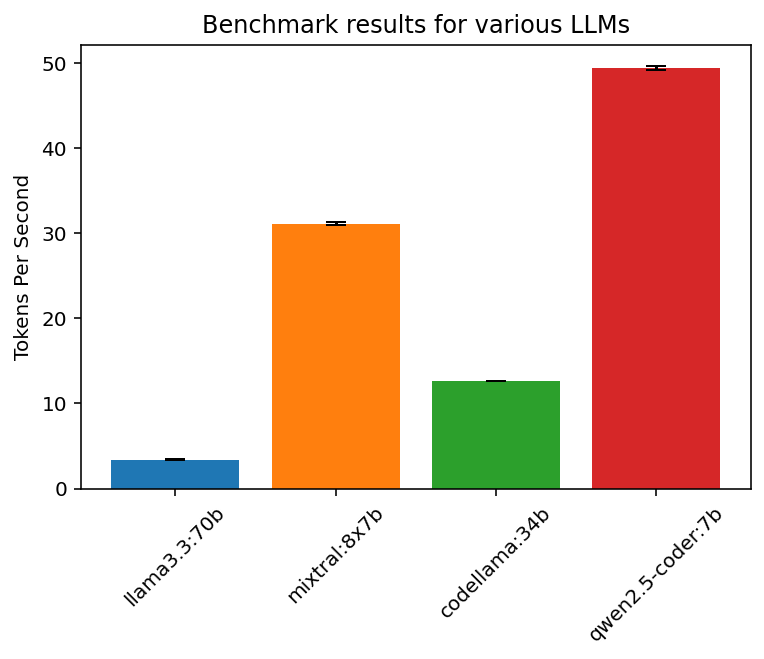
The results are summarized in a table below:
| Model Name | Loaded VRAM | Tokens/sec |
| llama3.3:70b | 43092MB | 3.37 |
| mixtral8x7b | 25344MB | 31.12 |
| codellama34b | 21500MB | 12.60 |
| qwen2.5-coder:7b | 5558MB | 49.41 |